Core thesis
Ideas do not scale by themselves. Frontier AI gains power where states and firms can assemble the system that turns ideas into training runs, inference fleets, and durable deployment.
Ideas do not scale by themselves. Frontier AI gains power where states and firms can assemble the system that turns ideas into training runs, inference fleets, and durable deployment.
At scale, AI capability depends on linked inputs rather than code alone. Once those inputs are named, the political stakes become easier to see.
AI capability at scale is produced by compute, energy, and data, then multiplied by scarce talent and by the efficiency gains that software can deliver.
Compute is both the most visible frontier input and the clearest example of how industrial concentration shapes AI power.
Frontier training runs now require clusters measured in tens of thousands of accelerators and expenditures measured in the hundreds of millions.
After compute is secured, electricity, grid access, and permitting often decide whether the cluster can operate.
A lab can have capital, chips, and ambition, yet still fail to scale if the grid cannot deliver reliable baseload power fast enough.
Water is a newer but increasingly important scaling condition: smaller in global share than electricity, but sharply concentrated where facilities actually sit.
Water matters because cooling load is local. A hyperscale campus does not compete against all freshwater use on earth; it competes inside a specific basin, permitting regime, and municipal infrastructure system.
Three dynamics explain why training material becomes governed: monetization and gatekeeping, localization, and quality scarcity.
Platforms, publishers, and states now compete over who can gate, license, localize, and legally define the data that matters most for training.
Talent is the paradoxical input: the scarcest in the short run and the most globally mobile at the same time.
Elite AI researchers and systems engineers are not produced on demand. Frontier talent is a long-cycle input that can take more than a decade to develop, which makes it resistant to quick policy fixes.
Efficiency matters because it destabilizes any simple story in which hardware denial automatically settles the balance of power.
Efficiency can erode the leverage of purely brute-force denial, even while infrastructure remains essential.
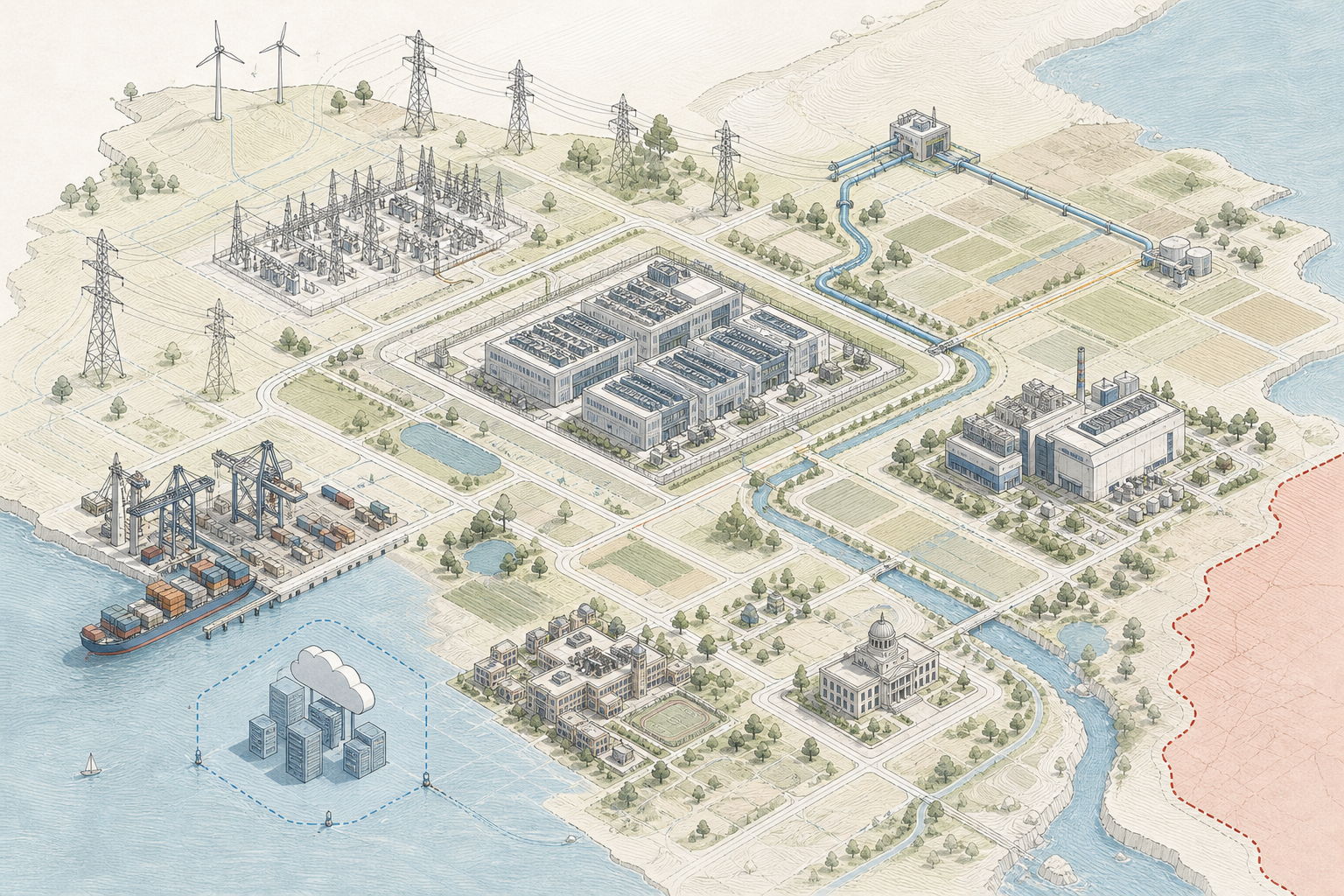
Only a narrow set of actors can turn compute, energy, data, talent, efficiency, and capital into frontier capability.
Frontier AI now requires more than a small team scaling on code quality: capital expenditure, cloud access, long-cycle infrastructure decisions, and the institutional ability to align regulators, suppliers, engineers, and financing.
Reading Spine
This module traces AI power from a conceptual reframing to the rival inputs that constrain it, then to the institutional logic that pushes the next module toward industrial policy.
Frontier AI turns code into usable power through an industrial system of compute, energy, data, talent, capital, and institutions.
Early scaling narratives treated models as if they were naturally diffusive: copyable, downloadable, and therefore difficult to territorialize. That intuition captures the non-rival character of ideas, but it misses the infrastructure that makes frontier capability real.
Training runs, inference fleets, cooling systems, curated datasets, power contracts, and operating teams all reintroduce rival constraints. AI therefore pulls geopolitics back toward an older grammar of industrial power: who owns the inputs, who controls the chokepoints, and who can deny scale to others.
Frontier advantage belongs to the state-firm assemblages that can mobilize the full production system behind model architecture.
Capability requires more than code. Rival inputs, institutions, and delivery systems must align in the same place.
Sovereignty returns where states and firms can govern access, cost, siting, and delivery across that full pipeline.
The industrial stack
How sovereignty re-entersAccelerators and clusters
Chips, networking, and integration define the first hard gate.
Power and cooling
Grid access decides whether compute can become operational scale.
Rights and access
Training inputs arrive through licensing, governance, and control.
Capital, cloud, permits, procurement
Capital, cloud contracts, permits, and procurement turn separate inputs into one deployable system.
Research and operations
Frontier teams remain scarce, mobile, and institutionally sticky.
Software multiplier
Better training recipes and system design change how far inputs can go.
Frontier capability
Training runs, inference fleets, and durable deployment depend on all of the above.
At scale, AI capability depends on linked inputs rather than code alone. Once those inputs are named, the political stakes become easier to see.
AI capability at scale is produced by compute, energy, and data, then multiplied by scarce talent and by the efficiency gains that software can deliver.
Frontier chips, cloud clusters, networking, and integration; scarce access becomes leverage.
Firm electricity, interconnection, transmission, and permits; compute scales where power arrives.
Licensed corpora, platform data, public datasets, and domain records; access is governed.
A limited pool of researchers, systems engineers, and operators able to build and run frontier systems.
MoE, distillation, data filtering, and training-stack optimization; scarce inputs go further.
Compute is both the most visible frontier input and the clearest example of how industrial concentration shapes AI power.
Frontier training runs now require clusters measured in tens of thousands of accelerators and expenditures measured in the hundreds of millions. That immediately narrows the field to actors with unusual access to capital and supply.
The stack is concentrated at multiple layers. Recent industry estimates commonly put NVIDIA above four-fifths of the AI accelerator or datacenter GPU market, while TrendForce put TSMC at about 70% of top-10 foundry revenue in late 2025. Memory, networking, and datacenter engineering add further bottlenecks to the path from chip design to usable capability.
Compute therefore works in two ways at once: a capital moat for frontier labs, and a policy chokepoint for states that can regulate access to chips, tools, and cloud pathways.
Frontier clusters now run from roughly 10,000 to 100,000 GPUs at the high end of current training scale.
NVIDIA is commonly estimated above 80% in AI accelerators or datacenter GPUs; TSMC held about 70% of top-10 foundry revenue in late 2025.
Training frontier-scale systems can require roughly $100M-$500M runs, before inference buildout.
Frontier capability starts with a narrow accelerator market dominated by a small number of suppliers.
Cutting-edge logic manufacturing remains geographically concentrated and difficult to replicate quickly.
HBM and high-bandwidth networking determine whether chips can operate as a coherent training cluster.
Cooling, power delivery, and cluster integration turn components into reliable frontier-scale compute.
Compute supply chain
Design to deploymentAccelerator design
A dominant accelerator supplier shapes the first bottleneck for frontier clusters.
Advanced fabrication
Leading-edge manufacturing concentrates the second gate in a narrow geography.
HBM & interconnect
Memory and networking decide whether chips can act as one coherent cluster.
Datacenter integration
Cooling, power, and cluster engineering turn procurement into usable capability.
A sequence of narrow gates makes compute simultaneously a capital moat and a policy lever.
After compute is secured, electricity, grid access, and permitting often decide whether the cluster can operate.
Energy now sits at the center of the production function because AI deployment is becoming power intensive at system scale. Public agencies, grid regulators, and utility filings describe the pressure from different angles: IEA projects sharp global growth through 2030, EIA links recent U.S. demand growth to data centers, and FERC treats co-location as a reliability and cost-allocation issue.
This is where the idea of stranded intelligence becomes useful. A lab can have capital, chips, and ambition, yet still fail to scale if the grid cannot deliver reliable baseload power fast enough.
The political consequence is that power delivery, co-location, transmission, and rate allocation stop looking like background infrastructure. They become part of AI strategy itself. Current firm-power examples make the scale concrete: Google, Kairos, and TVA target 500 MW of advanced nuclear capacity by 2035, Meta has framed nuclear procurement at up to 6.6 GW by 2035, and the Crane restart ties legacy nuclear capacity to Microsoft demand.
IEA, EIA, FERC, grid operators, and utility filings all point to the same regional pressure: datacenter load is becoming a material driver of power planning.
Connection queues, co-location disputes, and reliability concerns shift AI expansion into the terrain of grid governance and public regulation.
Hyperscalers and their partners increasingly seek always-on supply through nuclear restarts, advanced reactor partnerships, and long-horizon power agreements.
Constraint to response
Power becomes strategyAI load growth
Training and inference push datacenter demand into long-horizon planning.
Grid congestion
Queues, co-location fights, and transmission limits create stranded intelligence.
Firm-power deals
Hyperscalers seek nuclear, advanced reactors, and regulatory accommodation.
Scarcity arrives first; firm-power deals follow as the corporate response.
Water is a newer but increasingly important scaling condition: smaller in global share than electricity, but sharply concentrated where facilities actually sit.
Water matters because cooling load is local. A hyperscale campus does not compete against all freshwater use on earth; it competes inside a specific basin, permitting regime, and municipal infrastructure system.
The policy issue is siting politics rather than planetary spectacle. In water-stressed regions, a large datacenter can trigger fights over cooling methods, recycling systems, and who bears the local burden of AI expansion.
The result is a new marginal advantage for locations that can pair firm power with water resilience. Cooling technology, wastewater reuse, and basin stress start to matter alongside price and latency.
Three dynamics explain why training material becomes a governed asset: monetization and gatekeeping, localization, and quality scarcity.
Easy web-scale scraping was always a transitional condition, not a permanent settlement. As frontier systems exhaust cheap public text and shift toward higher-quality reasoning corpora, data rights become harder to separate from market power and institutional control.
Platforms, publishers, and states now compete over who can gate, license, localize, and legally define the data that matters most for training. Data still flows under terms that are politically contested.
From open extraction to governed flows
How data is reroutedOpen web text
Cheap public corpora powered early scaling.
Platform data
Feeds, forums, and archives become negotiable assets.
Industrial telemetry
Operational records gain value as AI moves into firms and infrastructure.
Licensing, localization, litigation
Contracts, jurisdiction, and legal conflict filter access.
Training pipeline
Training inputs become priced, filtered, or domestically bounded.
Platforms can shift from open extraction toward priced APIs, licensing, and explicit rules about AI training use.
States increasingly treat public-service, health, education, and defense-relevant datasets as sovereignty resources rather than frictionless inputs.
High-quality human data, proprietary feedback loops, and industrial telemetry gain value as generic web text saturates.
The New York Times complaint leaves the legal question open while showing that training-data access now sits inside copyright conflict and legal risk.
Talent is the paradoxical input: the scarcest in the short run and the most globally mobile at the same time.
Elite AI researchers and systems engineers are not produced on demand. Frontier talent is a long-cycle input that can take more than a decade to develop, which makes it resistant to quick policy fixes.
That scarcity interacts with global mobility. States want the gains from openness when they are trying to attract frontier talent, but they also want tighter control when AI becomes securitized.
The result is a sovereignty dilemma rather than a simple race: how much openness can a system retain while still treating frontier AI as a security domain?
MacroPolo separates origin from workplace: China produces the largest share of top AI researchers by undergraduate training, while the United States remains the leading workplace destination.
Open systems attract globally mobile researchers and engineers, making immigration and research ecosystems national assets.
Securitization, loyalty tests, and restrictive controls can protect against leakage, but they also risk degrading the openness that makes the system attractive.
Efficiency matters because it destabilizes any simple story in which hardware denial automatically settles the balance of power.
If capability can improve with less compute and less energy, export controls do not end the competition. They also create adaptation pressure: constrained actors have a stronger reason to innovate on software, model design, and training recipes.
Recent model releases keep pushing the same cost-capability dynamic. Efficiency can erode the leverage of purely brute-force denial, even while compute and infrastructure remain essential.
The techniques below are the mechanisms through which efficiency changes the production function.
Large parameter counts can route only part of the model for each token, reducing cost per inference and per training step.
Capabilities learned by large models can be compressed into smaller systems, widening diffusion below the absolute frontier.
Data quality filtering, better load balancing, and architectural tuning can substitute for brute-force scale only up to a point, but they matter.
DeepSeek-V3 and R1 made visible a broader efficiency frontier. Architecture choices, reinforcement learning, routing, distillation, data curation, and systems optimization can produce substantial capability gains under tighter hardware constraints.
This shifts policy analysis. Chip controls can raise costs and slow access; they also increase the incentive to use less compute per unit of capability.
DeepSeek reported a $5.6M direct training cost for V3. Frontier training runs are often discussed in the $100M-$500M range. The categories differ, but the contrast explains why efficiency can weaken hardware chokepoints without removing them.
Chokepoint leverage erodes over time because denial keeps generating adaptation incentives and software spreads more easily than fabs or grids.
Compute concentration retains its force because the frontier remains stubbornly capital intensive and physically bottlenecked.
Only a narrow set of actors can turn compute, energy, data, talent, efficiency, and capital into frontier capability.
Frontier AI now requires more than a small team scaling on code quality: capital expenditure, cloud access, long-cycle infrastructure decisions, and the institutional ability to align regulators, suppliers, engineers, and financing.
That is why frontier AI is an organizational feat as much as a scientific one. States cannot simply declare AI power into existence; they must build the enabling industrial system or bargain with the firms that already command it.
Once AI is understood as an industrial production function, state action follows a clear logic. Governments use subsidies, export controls, procurement, permits, and talent policy to build, protect, and route the inputs this module has defined.
These references track the module architecture used on the page: the production-function baseline, compute chokepoints, the energy and water constraints of scale, the enclosure of data, and efficiency as the main counter-force to pure denial.